
Industry-leading threat protection, supercharged by AI
Mimecast blends advanced AI with proven defenses to deliver industry-leading protection against emerging threats.
Collaborate securely by staying ahead of threats with AI-powered email security.




Powered by decades of experience, our global threat intelligence network, and powerful machine learning, our products (much like your team) will only get better with time.

Defend against the most sophisticated email attacks and stay ahead of threats.


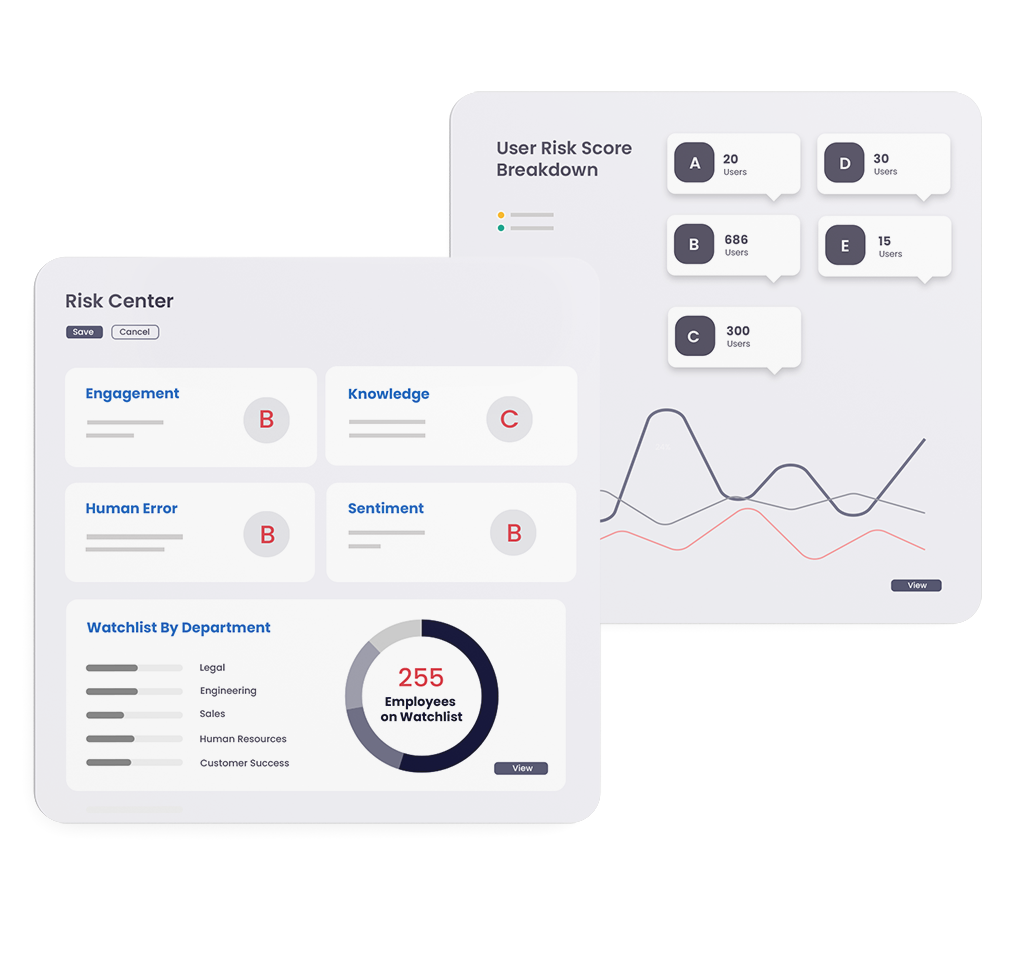
Invest in your human risk surface with award-winning, realistic, and effective training, simulations, and risk scoring.

Keep viruses, malware and phishing out of Microsoft Teams, Sharepoint, and OneDrive with this easy-to-deploy, easy-to-administer solution.


Simplify e-discovery & compliance, streamline IT environments, and ensure data is never lost.


Gain control of your email domains, increase email deliverability, and put an end to spoofing attacks.



Mimecast blends advanced AI with proven defenses to deliver industry-leading protection against emerging threats.
Mimecast is proud to protect and support 42,000+ organizations globally, helping them navigate the ever-expanding threat landscape since 2003.


Mimecast supports customers around the globe through a vast network of resellers, distributors, and managed service providers.

Our technology alliance partners help customers bring together some of the world's leading cybersecurity platforms to make integrated, AI-powered security a reality.




